PySpark and Latent Dirichlet Allocation - LDA for Topic Modeling
This past semester, I had the chance to take two courses: Statistical Machine Learning from a Probabilistic Perspective (it’s a bit of a mouthful) and Big Data Science & Capstone. In the former, we had the chance to study the breadth of various statistical machine learning algorithms and processes that have flourished in recent years. This included a number of different topics ranging from Gaussian Mixture Models to Latent Dirichlet Allocation. In the latter, our class divided into groups to work on a capstone project with one of a number of great companies or organizations. It was only a 3 credit-hour course, so it was a less intensive project than a traditional capstone course that is a student’s sole focus for an entire semester, but it was a great experience nonetheless. The Big Data science course taught us some fundamentals with big data science and normal data analysis (ETL, MapReduce, Hadoop, Weka, etc.) and then released us off into the wild blue yonder to see what we could accomplish with our various projects.
For the Big Data course, my team was actually assigned two projects:
- Attempting to track illness and outbreaks using social media
- Creating a module for Apache PySpark to conduct Sensitivity Analysis of
pyspark.mlmodels
Both of these projects involved the use of Apache PySpark, and as a result I came to become familiar with it at a basic level. For a final project within the Statistical Machine Learning class, I considered how I could bring the experience of both together, and thought of using the LDA capabilities of PySpark in order to model some of the social media data that my Big Data group had already gathered. An idea of mine was that if we could cluster the social media content, then we could find further patterns or filter out bad data, for example. That said, when my class attempted to implement LDA models ourselves, it took a considerable amount of time to process, but I felt that using PySpark on a cluster of computers would allow me to utilize a respectable amount of the social media data we had gathered. I came across a few tutorials and examples of using LDA within Spark, but all of them that I found were written using Scala. It is not a very difficult leap from Spark to PySpark, but I felt that a version for PySpark would be useful to some.
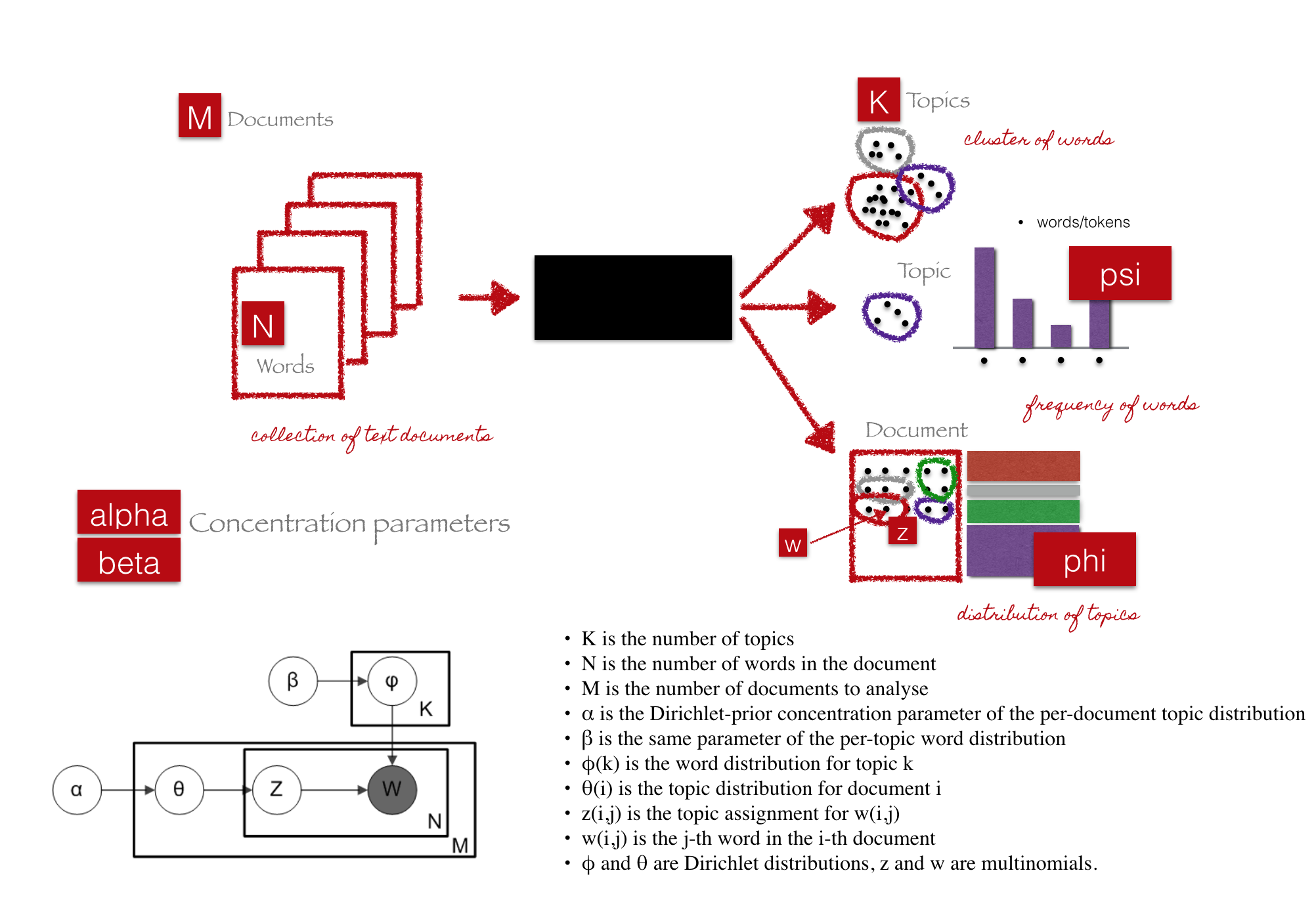
Summary explanation of Latent Dirichlet Allocation
The article that I mostly referenced when completing my own analysis can be found here: Topic modeling with LDA: MLlib meets GraphX. There, Joseph Bradley gives an apt description of what topic modeling is, how LDA covers it and what it could be used for. I’ll attempt to briefly summarize his remarks and refer you to the Databrick’s blog and other resources for deeper coverage. Topic modeling attempts to take “documents”, whether they are actual documents, sentences, tweets, etcetera, and infer the topic of the document. LDA attempts to do so by interpreting topics as unseen, or latent, distributions over all of the possible words (vocabulary) in all of the documents (corpus). This was originally developed for text analysis, but is being used in a number of different fields.
Example in PySpark
This example will follow the LDA example given in the Databrick’s blog post, but it should be fairly trivial to extend to whatever corpus that you may be working with. In this example, we will take articles from 3 newsgroups, process them using the LDA functionality of pyspark.mllib and see if we can validate the process by recognizing 3 distinct topics.
The step is to gather your corpus together. As I previously mentioned, we’ll use the discussions from 3 newsgroups. The entire set can be found here: 20 Newsgroups. For this example, I picked 3 topics that seem to be fairly distinct from each other:
- comp.os.ms-windows.misc
- rec.sport.baseball
- talk.religion.misc
I extracted the collection of discussions, and then put all of the discussions into one directory to form my corpus. Then we can point the PySpark script to this directory to pull the documents in. The entirety of the code used in this example can be found at the bottom of this post.
The first actual bit of code will initialize our SparkContext:
from collections import defaultdict
from pyspark import SparkContext
from pyspark.mllib.linalg import Vector, Vectors
from pyspark.mllib.clustering import LDA, LDAModel
from pyspark.sql import SQLContext
import re
num_of_stop_words = 50 # Number of most common words to remove, trying to eliminate stop words
num_topics = 3 # Number of topics we are looking for
num_words_per_topic = 10 # Number of words to display for each topic
max_iterations = 35 # Max number of times to iterate before finishing
# Initialize
sc = SparkContext('local', 'PySPARK LDA Example')
sql_context = SQLContext(sc)Then we’ll pull in the data and tokenize it to form our global vocabulary:
data = sc.wholeTextFiles('newsgroup/files/*').map(lambda x: x[1])
tokens = data \
.map( lambda document: document.strip().lower()) \
.map( lambda document: re.split("[\s;,#]", document)) \
.map( lambda word: [x for x in word if x.isalpha()]) \
.map( lambda word: [x for x in word if len(x) > 3] )Here we process the corpus by doing the following:
- Load each file as an individual document
- Strip any leading or trailing whitespace
- Convert all characters into lowercase where applicable
- Split each document into words, separated by whitespace, semi-colons, commas, and octothorpes
- Only keep the words that are all alphabetical characters
- Only keep words larger than 3 characters
This then leaves us with each document represented as a list of words that are hopefully more insightful than words like “the”, “and”, and other small words that we suspect are inconsequential to the topics we are hoping to find. The next step is to then generate our global vocabulary:
# Get our vocabulary
# 1. Flat map the tokens -> Put all the words in one giant list instead of a list per document
# 2. Map each word to a tuple containing the word, and the number 1, signifying a count of 1 for that word
# 3. Reduce the tuples by key, i.e.: Merge all the tuples together by the word, summing up the counts
# 4. Reverse the tuple so that the count is first...
# 5. ...which will allow us to sort by the word count
termCounts = tokens \
.flatMap(lambda document: document) \
.map(lambda word: (word, 1)) \
.reduceByKey( lambda x,y: x + y) \
.map(lambda tuple: (tuple[1], tuple[0])) \
.sortByKey(False)The above code performs the following steps:
- Flattens the corpus, aggregating all of the words into one giant list of words
- Maps each word with the number
1, indicate we count this word once - Reduce each word count, by finding all of the instances of any given word, and adding up their respective counts
- Invert each tuple, so that the word count precedes each word…
- …which then allows us to sort by the count for each word.
We now have a sorted list of tuples, sorted in descending order of the number of time each word is in the corpus. We can then use this to remove the most common words, which will most likely be commons words (like “the”, “and”, “from”) that are most likely not distinctive to any given topic, and are equally likely to be found in all of the topics. We then identify which words to remove by setting deciding to remove k amount of words, find the count of word that is k deep in the list, and then removing any words with that amount or more of occurrences in the vocabulary. After this, we will then index each word, giving each word a unique id and then collect them into a map:
# Identify a threshold to remove the top words, in an effort to remove stop words
threshold_value = termCounts.take(num_of_stop_words)[num_of_stop_words - 1][0]
# Only keep words with a count less than the threshold identified above,
# and then index each one and collect them into a map
vocabulary = termCounts \
.filter(lambda x : x[0] < threshold_value) \
.map(lambda x: x[1]) \
.zipWithIndex() \
.collectAsMap()This leaves us with a vocabulary that consists of tuples of words and their word counts, with the most common words removed. The next step is to represent each document as a vector of word counts. What this means is that instead of each document being formed of a sequence of words, we will have a list that is the size of the global vocabulary, and the value of each cell is the count of the word whose id is the index of that cell:
# Convert the given document into a vector of word counts
def document_vector(document):
id = document[1]
counts = defaultdict(int)
for token in document[0]:
if token in vocabulary:
token_id = vocabulary[token]
counts[token_id] += 1
counts = sorted(counts.items())
keys = [x[0] for x in counts]
values = [x[1] for x in counts]
return (id, Vectors.sparse(len(vocabulary), keys, values))
# Process all of the documents into word vectors using the
# `document_vector` function defined previously
documents = tokens.zipWithIndex().map(document_vector).map(list)The final thing to do before actually beginning to run the model is to invert our vocabulary so that we can lookup each word based on it’s id. This will allow us to see which words strongly correlate to which topics:
# Get an inverted vocabulary, so we can look up the word by it's index value
inv_voc = {value: key for (key, value) in vocabulary.items()}Now we open an output file, and train our model on the corpus with the desired amount of topics and maximum number of iterations:
# Open an output file
with open("output.txt", 'w') as f:
lda_model = LDA.train(documents, k=num_topics, maxIterations=max_iterations)
topic_indices = lda_model.describeTopics(maxTermsPerTopic=num_words_per_topic)
# Print topics, showing the top-weighted 10 terms for each topic
for i in range(len(topic_indices)):
f.write("Topic #{0}\n".format(i + 1))
for j in range(len(topic_indices[i][0])):
f.write("{0}\t{1}\n".format(inv_voc[topic_indices[i][0][j]] \
.encode('utf-8'), topic_indices[i][1][j]))
f.write("{0} topics distributed over {1} documents and {2} unique words\n" \
.format(num_topics, documents.count(), len(vocabulary)))Obviously, you can take the output and do with it what you will, but here we will get an output file called output.txt which will list each of our three topics that we are hoping to see. You can play around with the num_topics to see how the model reacts, but since we know we have discussions that center around three distinct topics, we would have that having 3 topics would reflect that by clustering around words that align with each of those topics separately.
The continuation of this is to gather “unlabeled” data (as much as this can be called labeled), and to use LDA to perform topic modeling on your newly found corpus. I’m still learning on how to go about that, but hopefully this has been of some help to anyone looking to get started with PySpark LDA.
Appendix: Here’s the code
from collections import defaultdict
from pyspark import SparkContext
from pyspark.mllib.linalg import Vector, Vectors
from pyspark.mllib.clustering import LDA, LDAModel
from pyspark.sql import SQLContext
import re
num_of_stop_words = 50 # Number of most common words to remove, trying to eliminate stop words
num_topics = 3 # Number of topics we are looking for
num_words_per_topic = 10 # Number of words to display for each topic
max_iterations = 35 # Max number of times to iterate before finishing
# Initialize
sc = SparkContext('local', 'PySPARK LDA Example')
sql_context = SQLContext(sc)
# Process the corpus:
# 1. Load each file as an individual document
# 2. Strip any leading or trailing whitespace
# 3. Convert all characters into lowercase where applicable
# 4. Split each document into words, separated by whitespace, semi-colons, commas, and octothorpes
# 5. Only keep the words that are all alphabetical characters
# 6. Only keep words larger than 3 characters
data = sc.wholeTextFiles('newsgroup/files/*').map(lambda x: x[1])
tokens = data \
.map( lambda document: document.strip().lower()) \
.map( lambda document: re.split("[\s;,#]", document)) \
.map( lambda word: [x for x in word if x.isalpha()]) \
.map( lambda word: [x for x in word if len(x) > 3] )
# Get our vocabulary
# 1. Flat map the tokens -> Put all the words in one giant list instead of a list per document
# 2. Map each word to a tuple containing the word, and the number 1, signifying a count of 1 for that word
# 3. Reduce the tuples by key, i.e.: Merge all the tuples together by the word, summing up the counts
# 4. Reverse the tuple so that the count is first...
# 5. ...which will allow us to sort by the word count
termCounts = tokens \
.flatMap(lambda document: document) \
.map(lambda word: (word, 1)) \
.reduceByKey( lambda x,y: x + y) \
.map(lambda tuple: (tuple[1], tuple[0])) \
.sortByKey(False)
# Identify a threshold to remove the top words, in an effort to remove stop words
threshold_value = termCounts.take(num_of_stop_words)[num_of_stop_words - 1][0]
# Only keep words with a count less than the threshold identified above,
# and then index each one and collect them into a map
vocabulary = termCounts \
.filter(lambda x : x[0] < threshold_value) \
.map(lambda x: x[1]) \
.zipWithIndex() \
.collectAsMap()
# Convert the given document into a vector of word counts
def document_vector(document):
id = document[1]
counts = defaultdict(int)
for token in document[0]:
if token in vocabulary:
token_id = vocabulary[token]
counts[token_id] += 1
counts = sorted(counts.items())
keys = [x[0] for x in counts]
values = [x[1] for x in counts]
return (id, Vectors.sparse(len(vocabulary), keys, values))
# Process all of the documents into word vectors using the
# `document_vector` function defined previously
documents = tokens.zipWithIndex().map(document_vector).map(list)
# Get an inverted vocabulary, so we can look up the word by it's index value
inv_voc = {value: key for (key, value) in vocabulary.items()}
# Open an output file
with open("output.txt", 'w') as f:
lda_model = LDA.train(documents, k=num_topics, maxIterations=max_iterations)
topic_indices = lda_model.describeTopics(maxTermsPerTopic=num_words_per_topic)
# Print topics, showing the top-weighted 10 terms for each topic
for i in range(len(topic_indices)):
f.write("Topic #{0}\n".format(i + 1))
for j in range(len(topic_indices[i][0])):
f.write("{0}\t{1}\n".format(inv_voc[topic_indices[i][0][j]] \
.encode('utf-8'), topic_indices[i][1][j]))
f.write("{0} topics distributed over {1} documents and {2} unique words\n" \
.format(num_topics, documents.count(), len(vocabulary)))

{kind=link}
0 Comments