Explore Data Analysis - EDA Cơ Bản

Mục tiêu của cuộc thi Home credit của Kaggle là xây dựng được mô hình dự đoán (predictive model) có điểm đánh giá (evaluation metric) AUC cao. Một mô hình Machine Learning chỉ có thể xây dựng được khi dữ liệu đầu vào đã được chuẩn bị và xử lý tốt. Kaggle cho trước tập các bảng (table), nhiệm vụ của chúng ta là biến đổi và kết hợp chúng lại thành các đặc trưng (feature) có ý nghĩa để model có thể dự đoán tốt trên tập dữ liệu chưa nhìn thấy (test set, unseen data), kết quả thực tế (label) này được giữ bí mật trên Kaggle và dùng để đánh giá các đội trong cuộc thi.
Để có thể làm feature engineering tốt, bước đầu tiên ta cần quan sát và hiểu được dữ liệu. Ta sẽ sử dụng các kỹ thuật bên thống kê gồm các số liệu thống kê và biểu đồ (visualization). Explore Data Analysis (EDA) sẽ giúp ta đánh giá, lựa chọn và biến đổi dữ liệu thành feature phù hợp cho model.
Khi đã có các phân tích từ EDA, ta sẽ có những hướng giải quyết tốt hơn khi đối mặt với các vấn đề bên dưới:
- Dữ liệu bị NaN (Not a Number), Null (missing data), nguyên nhân từ đâu?
- Kiểu dữ liệu không khớp (e.g. 1990.0 là kiểu số thực nhưng load lên lại là kiểu string), nên ép kiểu như thế nào?
- Dữ liệu bị lặp (duplicate) nên chọn và bỏ bớt cái nào?
- Dữ liệu không liên quan, có phải do nhập sai?
- Dữ liệu bất thường (e.g. tuổi bị âm, huyết áp bằng không, ngày tháng không đúng format) nên biến đổi thế nào?
- Dữ liệu ở dạng categorical thì nên biến đổi bằng one-hot encoding hay mapping number?
- etc.
Descriptive Statistics
Đối với mỗi kiểu dữ liệu, ta sẽ quan tâm đến các độ đo khác nhau. Thông thường, ta có 2 loại dữ liệu, mỗi loại phân ra thành 2 kiểu con.
Categorical
- Nomial (nhãn): ví dụ tên trái cây (táo, cam, xoài), giới tính (nam, nữ), nhóm máu (A, B, AB, O).
Độ đo quan tâm: đếm tần suất xuất hiện (frequency), giá trị mode (độ phổ biến). - Ordinal (có thứ tự): ví dụ chất lượng các loại thịt (A, AA, AAA), mức độ bệnh (nhẹ, vừa, nặng).
Độ đo quan tâm: tương tự nominal nhưng có thêm luỹ tích (cumulative) và median (trung vị).
Metric (đo lường được)
- Discrete: số nguyên, thường áp dụng các phép đếm. Ví dụ như ngày tháng (16/9/2015), tọa độ địa lý (vĩ độ 47, kinh độ 122), tuổi tác, số lần khám bệnh mỗi năm.
Độ đo quan tâm: tương tự ordinal nhưng có thêm average (giá trị trung bình). - Continuous: số thực, thường áp dụng các phép đo lường. Ví dụ các độ đo vật lý như chiều dài, cân nặng.
Độ đo quan tâm: chia giỏ (bining), rời rạc hoá miền giá trị liên tục thành giá trị rời rạc (continuous sang ordinal). Khi đó, ta có thể áp dụng các số liệu bên ordinal cộng với 5-number summary (min/max, quantile 25 (lower), 50 (median), 75 (upper)).
Các số liệu khác mà ta quan tâm
- Số lượng thuộc tính: bảng dữ liệu đang xét có phức tạp hay không để ước lượng thời gian phân tích.
- Kích thước của bảng: có bao nhiêu dòng, bao nhiêu MB được lưu trên đĩa để ước lượng chi phí lưu trữ và tính toán.
- Số lượng giá trị distinct: xác định xem dữ liệu có bị duplicate hay không. Phân loại dữ liệu thuộc kiểu categorical hay descrete.
- Số lượng giá trị bị Null (missing data): xem xét có nên loại thuộc tính này ra không.
- Số lượng giá trị âm: phát hiện các thuộc tính có giá trị sai ngữ nghĩa (e.g. ngày tháng bị âm, thu nhập bị âm).
- Số lượng giá trị zeros: nếu có quá nhiều giá trị zeros thì thuộc tính này không mang lại nhiều giá trị cho feature engineering.
Data dictionary
Từ các số liệu thống kê được tổng hợp từ bên trên, ta hình thành được Data dictionary dùng để tiện tra cứu cho các phân tích sâu hơn. Thông thường, tôi sẽ lưu tất cả các phân tích và ghi chú này vào một file excel. Nếu có nhiều bảng, tôi sẽ lập một Sheet cho từng bảng. Cuối cùng, ta được một bảng report như bên dưới.
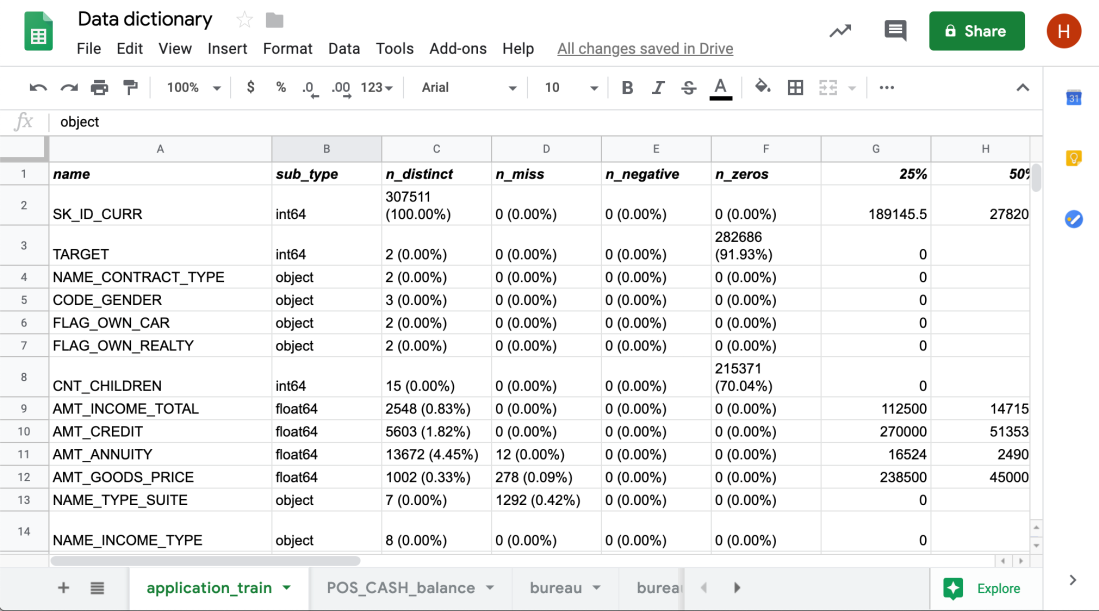
Tôi có tạo notebook hướng dẫn cách lập bảng report như bên trên tại đây. Điểm lợi có thể thấy từ việc tạo data dictionary:
- Tự động hoá lấy số liệu từ nhiều bảng khác nhau, giúp giảm thời gian phân tích lặp đi lặp lại.
- Truy cứu nhanh dữ liệu mà không cần chạy code lại từ đầu.
- Chia sẻ thông tin giữa các thành viên trong nhóm dễ dàng hơn.
Bên cạnh các thông tin trên, ta có thể lưu lại tiếp nhật ký nghiên cứu của mình. Thực hiện được như vậy, ta sẽ thấy được những vấn đề còn tồn động để giải quyết từ từ và không lặp lại những thực nghiệm đã hoàn tất.
- Những thắc mắc về dữ liệu mà bạn muốn phân tích kỹ hơn. Ví dụ, tại sao thời gian lại là số âm, ý nghĩa tên các thuộc tính thực chất là gì, mối quan hệ giữa các hồ sơ đi vay là như thế nào, etc.
- Những giả thuyết bạn đề ra, kết quả mà bạn dự đoán và thực tế thu được là gì. Việc này giúp bạn tránh được tư duy chủ quan về dữ liệu mà thực tế không phải như vậy. Ví dụ, bạn giả định nam giới là trụ cột của gia đình nên số lượng đi vay sẽ nhiều hơn nữ giới, nhưng thực tế sau khi phân tích bạn thấy nữ giới đi vay nhiều hơn hẳn nam giới.
- Những features mà bạn nảy ra trong lúc phân tích, dùng làm ý tưởng feture engineering sau này.
- Ghi chú lý do bạn thêm bớt dữ liệu, loại bỏ các thuộc tính vì nguyên nhân nào.
- Và các biểu đồ (visualization).
Visualization
Để có thể trình bày biểu đồ, ta cần ánh xạ tập các thuộc tính vào không gian biểu diễn. Ta thực hiện hai bước
- Nhận diện kiểu dữ liệu (categorical, metric).
- Chọn biểu đồ phù hợp với kiểu dữ liệu hiện tại.
Chọn biểu đồ phù hợp với kiểu dữ liệu hiện tại
Categorical
- Nominal: pie chart (số lượng label nhỏ), word cloud (số lượng label lớn), bar chart (clustered, stacked).
- Ordinal: như nominal và có thêm step chart (cumulative).
Metric
- Discrete: bar chart (clustered, stacked)
- Continuous: histogram (binning, discretizing), multiple histogram, cumulative histogram, box-plot (5-number summary)
Charts
Pie chart: thể hiện mối quan hệ theo phần trăm giữa các phần so với tổng thể. Thích hợp khi bạn muốn truyền tải sự phân bổ. Ví dụ, tỉ lệ phần trăm số lượng Male (M) vs Female (F). Ở đây, ta thấy F chiếm hơn 65%.

Word cloud: thường dùng khi số lượng categories nhiều. Category nào càng phổ biến thì kích thước hiển thị càng lớn. Ví dụ, word cloud thể hiện sự phổ biến của các bậc học. Ở đây, ta thấy bậc học “secondary” là phổ biến.

Bar chart: là biểu đồ dạng thanh đứng hoặc ngang dùng biểu thị số liệu và so sánh giữa các hạng mục (categories). Một trục dùng để biểu thị các categories, trục còn lại biểu thị các nấc giá trị riêng biệt. Ví dụ, số lượng Male (M) vs Female (F). Ở đây, ta thấy số lượng F chiếm ưu thế.

Bar chart (group): tương tự như bar chart nhưng được phân chia thêm các nhóm nhỏ hơn. Ví dụ, số lượng phân bố của người đi vay quịch nợ (1) và trả nợ (0) ở mỗi giới tính.

Bar chart (stacked): tương tự như bar chart (group) thay vì đặt các nhóm liền kề, ta đặt chúng xếp chồng lên nhau. Theo cách này, ta vừa biết được số lượng thật sự của nhóm cha (CODE_GENDER) vừa biết số lượng phân bố của từng nhóm con (TARGET).

Step chart (cumulative): dùng cho kiểu dữ liệu Ordinal và Descrete, các giá trị đã được sắp tăng dần trên trục số. Như vậy, đối với từng category ta xác định được luỹ tích từ trước đến giờ là bao nhiêu. Ví dụ, số lượng tiền vay tín dụng luỹ tích trong 5 tháng liên tiếp như thế nào.

Histogram: là biểu đồ thể hiện phân bố của các điểm dữ liệu. Ta chọn số lượng chia giỏ (bins) phù hợp để gom miền giá trị liên tục vào các khoảng đoạn. Tương đương với việc ta có Bar chart trên trục số đã được rời rạc hoá. Số lượng chia bin càng nhiều thì biểu đồ càng mịn, ngược lại biểu đồ sẽ thô hơn. Ví dụ, histogram của tín dụng theo từng bin.

Boxplot: thể hiện 5 giá trị chính trong miền số thực: Q1 – 1.5 * IQR, Q1 (25%), median, Q3 (75%), Q3 + 1.5 * IQR (IQR: InterQuartile Range = Q3 – Q1). Giúp phát hiện giá trị outliers. Ví dụ, boxplot cho phân bố giá trị của giá sản phẩm.
Scatter plot: thể hiện mối tương quan giữa 2 biến. Ví dụ, scatter plot giữa biến AMT_CREDIT và AMT_ANNUITY. Những biến có độ tương quan cao thì không nên áp dụng cùng phép thống kê

Bạn có thể đọc thêm các notebook trong chương Visualization trong khoá học Data science mini course bên dưới:


0 Comments