Topic modelling with LDA-(Latent Dirichlet Allocation) in Pyspark
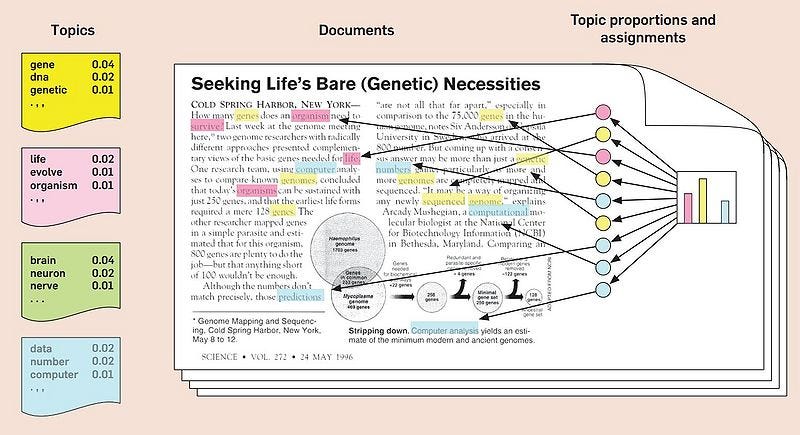
In one of the projects that I was a part of we had to find topics from millions of documents. You can try doing topic modelling using two methods. Do Non negative Matrix Factorization (NMF) or LDA. NMF is supposed to be a lot faster than LDA, but LDAs supposed to be more accurate. Problem is LDA takes a long time, unless you’re using distributed computing. Thats why I wanted to show you how you approach this problem using Spark in python.
I’m using a random table whose one columns has some sort of reviews for fashion items. You can use any corpus you want.
# check if spark context is defined
print(sc.version)Mine shows a really old version — 1.6.1 . So proceed with caution. Some of the libraries Im using might have changed a bit. First I import the following libraries and read the data.
# importing some librariesimport pandas as pd
import pyspark
from pyspark.sql import SQLContext
sqlContext = SQLContext(sc)# stuff we'll need for text processingfrom nltk.corpus import stopwords
import re as re
from pyspark.ml.feature import CountVectorizer , IDF# stuff we'll need for building the model
from pyspark.mllib.linalg import Vector, Vectors
from pyspark.mllib.clustering import LDA, LDAModel# reading the data
data = sqlContext.read.format("csv") \
.options(header='true', inferschema='true') \
.load(os.path.realpath("Womens Clothing E-Commerce Reviews.csv"))
Right now, Im reading the data as a dataframe. The I select the column which has the reviews and do some pre-processing on the text. Notice that reviews is an rdd.
reviews = data.map(lambda x : x['Review Text']).filter(lambda x: x is not None)StopWords = stopwords.words("english")tokens = reviews \
.map( lambda document: document.strip().lower()) \
.map( lambda document: re.split(" ", document)) \
.map( lambda word: [x for x in word if x.isalpha()]) \
.map( lambda word: [x for x in word if len(x) > 3] ) \
.map( lambda word: [x for x in word if x not in StopWords]) \
.zipWithIndex()
Let me take you step by step what Im doing here. First I select the column which has the reviews and remove all the empty rows.
Then I remove all the extra spaces between words, split each review into list of words, change them into lowercase, check if they’re alpha numeric, remove any words or typos which are less than three letters, remove any stopwords, and finally add an index to the elements.
Next Im going to build a TF-IDF matrix before I run the LDA. How you feed the data into the TF and IDF libraries in spark is a bit tricky. Thats why Im transforming the rdd into a DataFrame which has two columns — one has index and the other the list of words. CountVectorizer takes this data and returns a sparse matrix of term frequencies attached to the original Dataframe. Same thing goes for the IDF.
df_txts = sqlContext.createDataFrame(tokens, ["list_of_words",'index'])# TF
cv = CountVectorizer(inputCol="list_of_words", outputCol="raw_features", vocabSize=5000, minDF=10.0)
cvmodel = cv.fit(df_txts)result_cv = cvmodel.transform(df_txts)# IDFidf = IDF(inputCol="raw_features", outputCol="features")
idfModel = idf.fit(result_cv)
result_tfidf = idfModel.transform(result_cv)
You can run LDA on just the TF matrix if you want. Then I’d suggest remove the most common words which are likely to end up in all your topics. That way your topics will be more clean and interpretable.
Now that the data prep is done, time to run the model. Here I define how many topics and iterations I want and start the training.
num_topics = 10
max_iterations = 100lda_model = LDA.train(result_tfidf[['index','features']].map(list), k=num_topics, maxIterations=max_iterations)
Were almost done. Next we take a look at the top five words in each topics. You can print out more words for each topic to get a better idea. You can also see the weights of each word in a particular topic.
wordNumbers = 5 topicIndices = sc.parallelize(lda_model.describeTopics\(maxTermsPerTopic = wordNumbers))def topic_render(topic):
terms = topic[0]
result = []
for i in range(wordNumbers):
term = vocabArray[terms[i]]
result.append(term)
return resulttopics_final = topicIndices.map(lambda topic: topic_render(topic)).collect()for topic in range(len(topics_final)):
print ("Topic" + str(topic) + ":")
for term in topics_final[topic]:
print (term)
print ('\n')
And thats it! Thanks for making it to the end. Like and leave a comment if you thought this was helpful to you.

0 Comments