Topic Modeling in Power BI using PyCaret
In our last post, we demonstrated how to implement clustering analysis in Power BI by integrating it with PyCaret, thus allowing analysts and data scientists to add a layer of machine learning to their reports and dashboards without any additional license costs.
In this post, we will see how we can implement topic modeling in Power BI using PyCaret. If you haven’t heard about PyCaret before, please read this announcement to learn more.
Learning Goals of this Tutorial
- What is Natural Language Processing?
- What is Topic Modeling?
- Train and implement a Latent Dirichlet Allocation model in Power BI.
- Analyze results and visualize information in a dashboard.
Before we start
If you have used Python before, it is likely that you already have Anaconda Distribution installed on your computer. If not, click here to download Anaconda Distribution with Python 3.7 or greater.

Setting up the Environment
Before we start using PyCaret’s machine learning capabilities in Power BI we have to create a virtual environment and install pycaret. It’s a four-step process:
✅ Step 1 — Create an anaconda environment
Open Anaconda Prompt from start menu and execute the following code:
conda create --name powerbi python=3.7“powerbi” is the name of environment we have chosen. You can keep whatever name you would like.
✅ Step 2 — Install PyCaret
Execute the following code in Anaconda Prompt:
pip install pycaretInstallation may take 15–20 minutes. If you are having issues with installation, please see our GitHub page for known issues and resolutions.
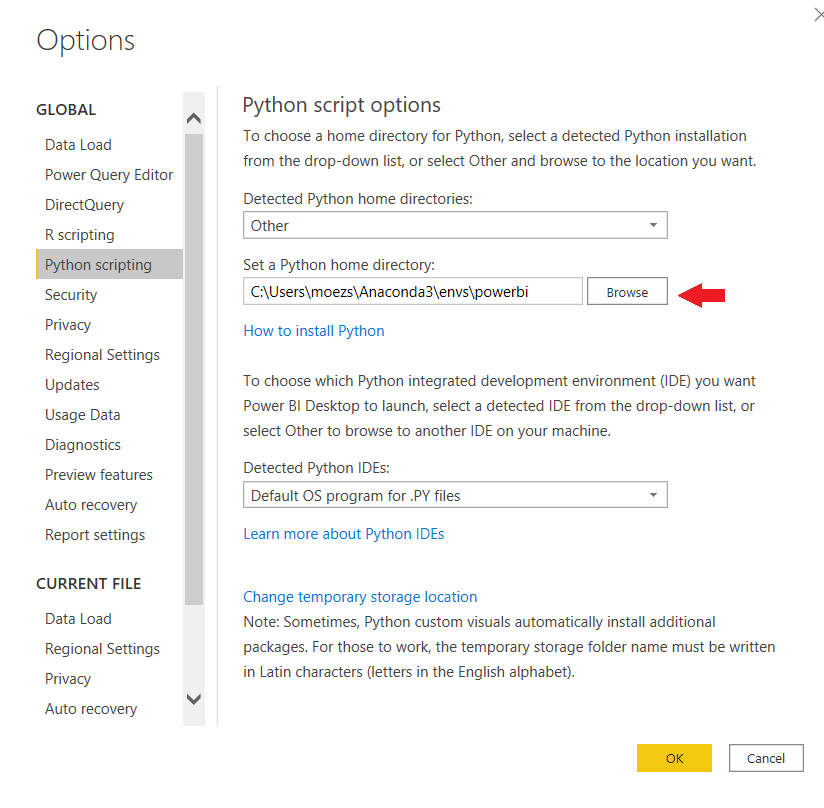
✅Step 3 — Set Python Directory in Power BI
The virtual environment created must be linked with Power BI. This can be done using Global Settings in Power BI Desktop (File → Options → Global → Python scripting). Anaconda Environment by default is installed under:
C:\Users\username\Anaconda3\envs\
✅Step 4 — Install Language Model
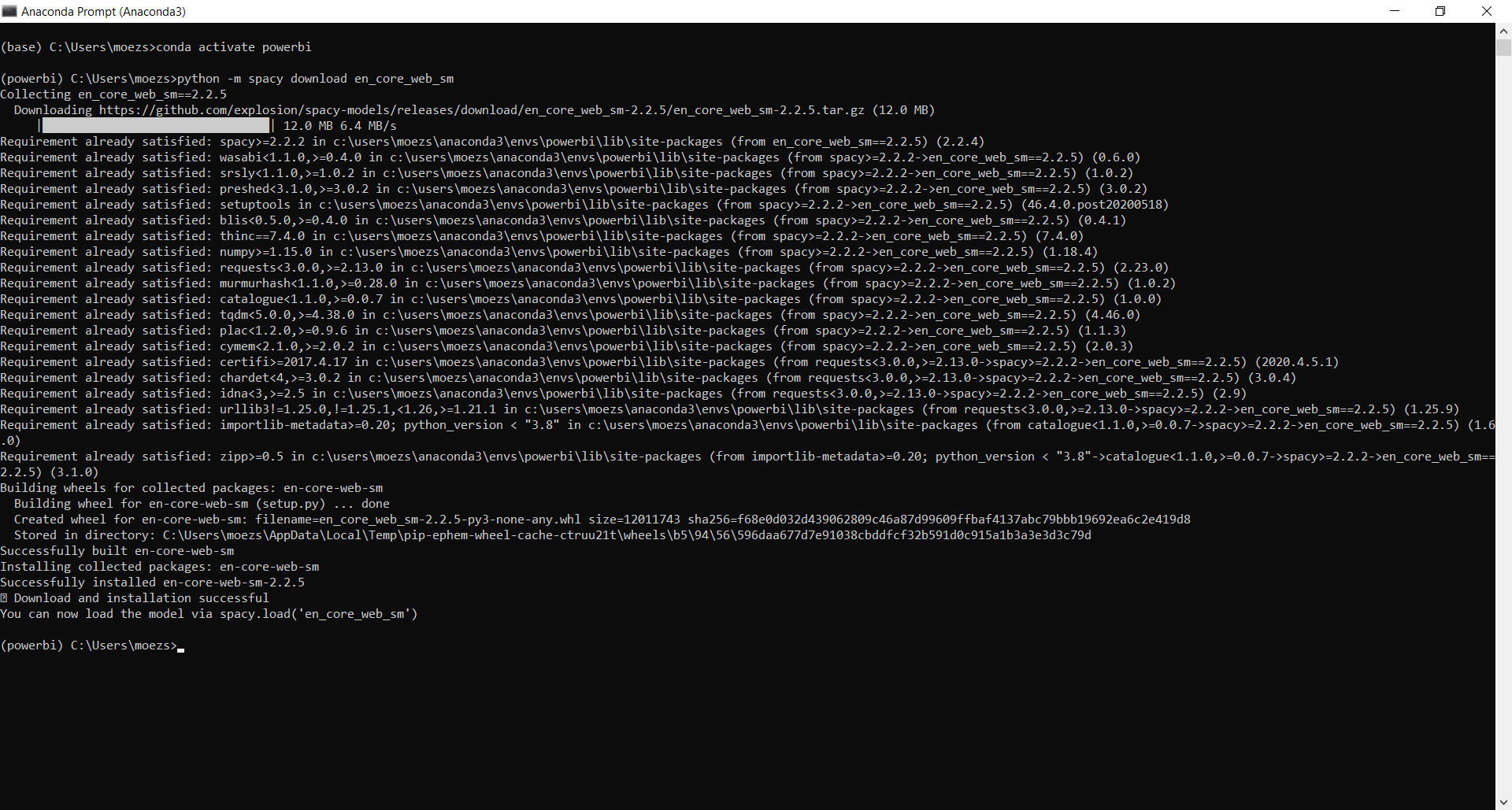
In order to perform NLP tasks you must download language model by executing following code in your Anaconda Prompt.
First activate your conda environment in Anaconda Prompt:
conda activate powerbiDownload English Language Model:
python -m spacy download en_core_web_sm
python -m textblob.download_corpora

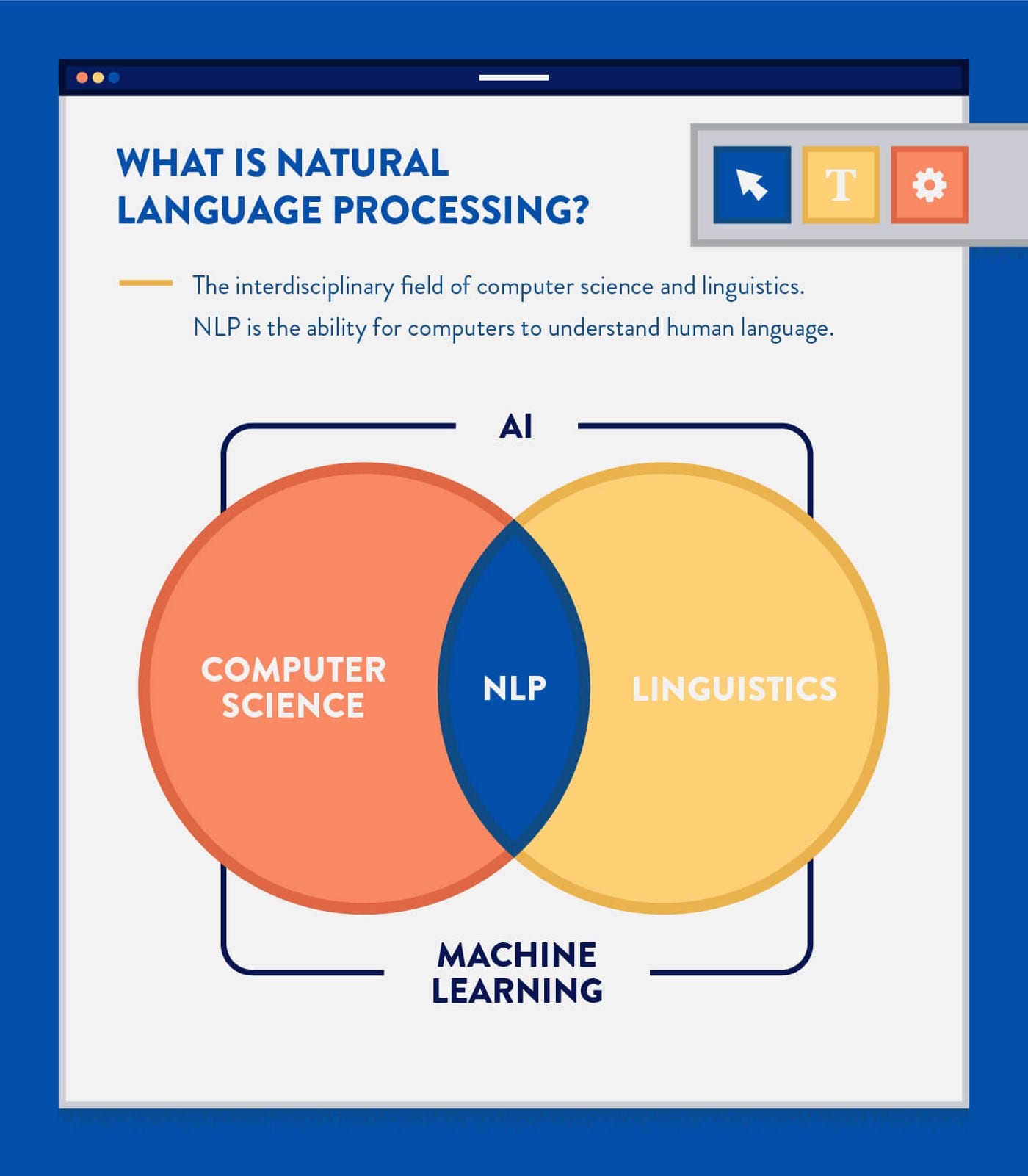
What is Natural Language Processing?
Natural language processing (NLP) is a subfield of computer science and artificial intelligence that is concerned with the interactions between computers and human languages. In particular, NLP covers broad range of techniques on how to program computers to process and analyze large amounts of natural language data.
NLP-powered software helps us in our daily lives in various ways and it is likely that you have been using it without even knowing. Some examples are:
- Personal assistants: Siri, Cortana, Alexa.
- Auto-complete: In search engines (e.g: Google, Bing, Baidu, Yahoo).
- Spell checking: Almost everywhere, in your browser, your IDE (e.g: Visual Studio), desktop apps (e.g: Microsoft Word).
- Machine Translation: Google Translate.
- Document Summarization Software: Text compactor, Autosummarizer.

Topic Modeling is a type of statistical model used for discovering abstract topics in text data. It is one of many practical applications within NLP.
What is Topic Modeling?
A topic model is a type of statistical model that falls under unsupervised machine learning and is used for discovering abstract topics in text data. The goal of topic modeling is to automatically find the topics / themes in a set of documents.
Some common use-cases for topic modeling are:
- Summarizing large text data by classifying documents into topics (the idea is pretty similar to clustering).
- Exploratory Data Analysis to gain understanding of data such as customer feedback forms, amazon reviews, survey results etc.
- Feature Engineering creating features for supervised machine learning experiments such as classification or regression
There are several algorithms used for topic modeling. Some common ones are Latent Dirichlet Allocation (LDA), Latent Semantic Analysis (LSA), and Non-Negative Matrix Factorization (NMF). Each algorithm has its own mathematical details which will not be covered in this tutorial. We will implement a Latent Dirichlet Allocation (LDA) model in Power BI using PyCaret’s NLP module.
If you are interested in learning the technical details of the LDA algorithm, you can read this paper.
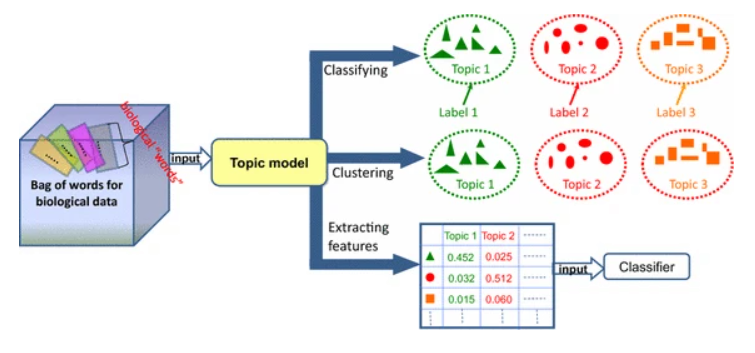
Text preprocessing for Topic Modeling
In order to get meaningful results from topic modeling text data must be processed before feeding it to the algorithm. This is common with almost all NLP tasks. The preprocessing of text is different from the classical preprocessing techniques often used in machine learning when dealing with structured data (data in rows and columns).
PyCaret automatically preprocess text data by applying over 15 techniques such as stop word removal, tokenization, lemmatization, bi-gram/tri-gram extraction etc. If you would like to learn more about all the text preprocessing features available in PyCaret, click here.
Setting the Business Context
Kiva is an international non-profit founded in 2005 in San Francisco. Its mission is to expand financial access to underserved communities in order to help them thrive.

In this tutorial we will use the open dataset from Kiva which contains loan information on 6,818 approved loan applicants. The dataset includes information such as loan amount, country, gender and some text data which is the application submitted by the borrower.

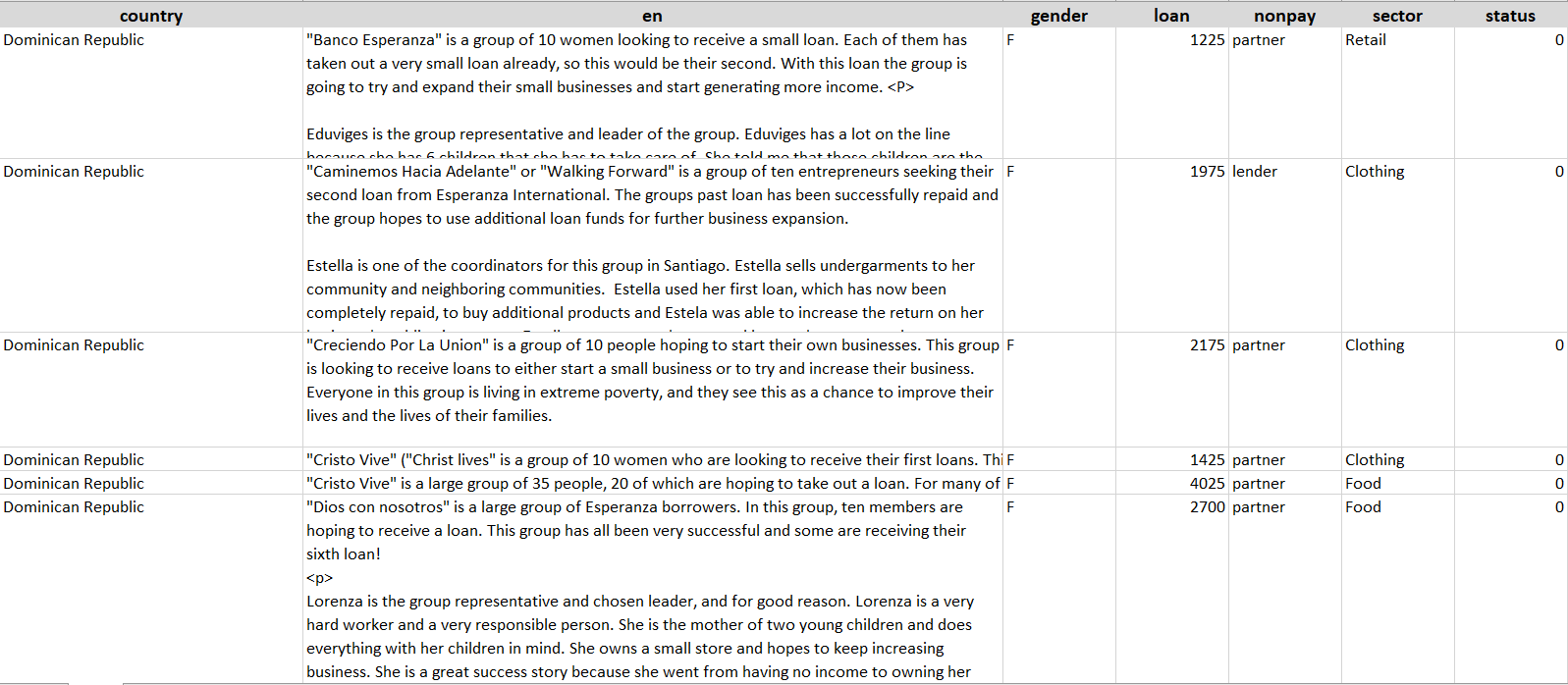
Our objective is to analyze the text data in the ‘en’ column to find abstract topics and then use them to evaluate the effect of certain topics (or certain types of loans) on the default rate.
👉 Let’s get started
Now that you have set up the Anaconda Environment, understand topic modeling and have the business context for this tutorial, let’s get started.
1. Get Data
The first step is importing the dataset into Power BI Desktop. You can load the data using a web connector. (Power BI Desktop → Get Data → From Web).
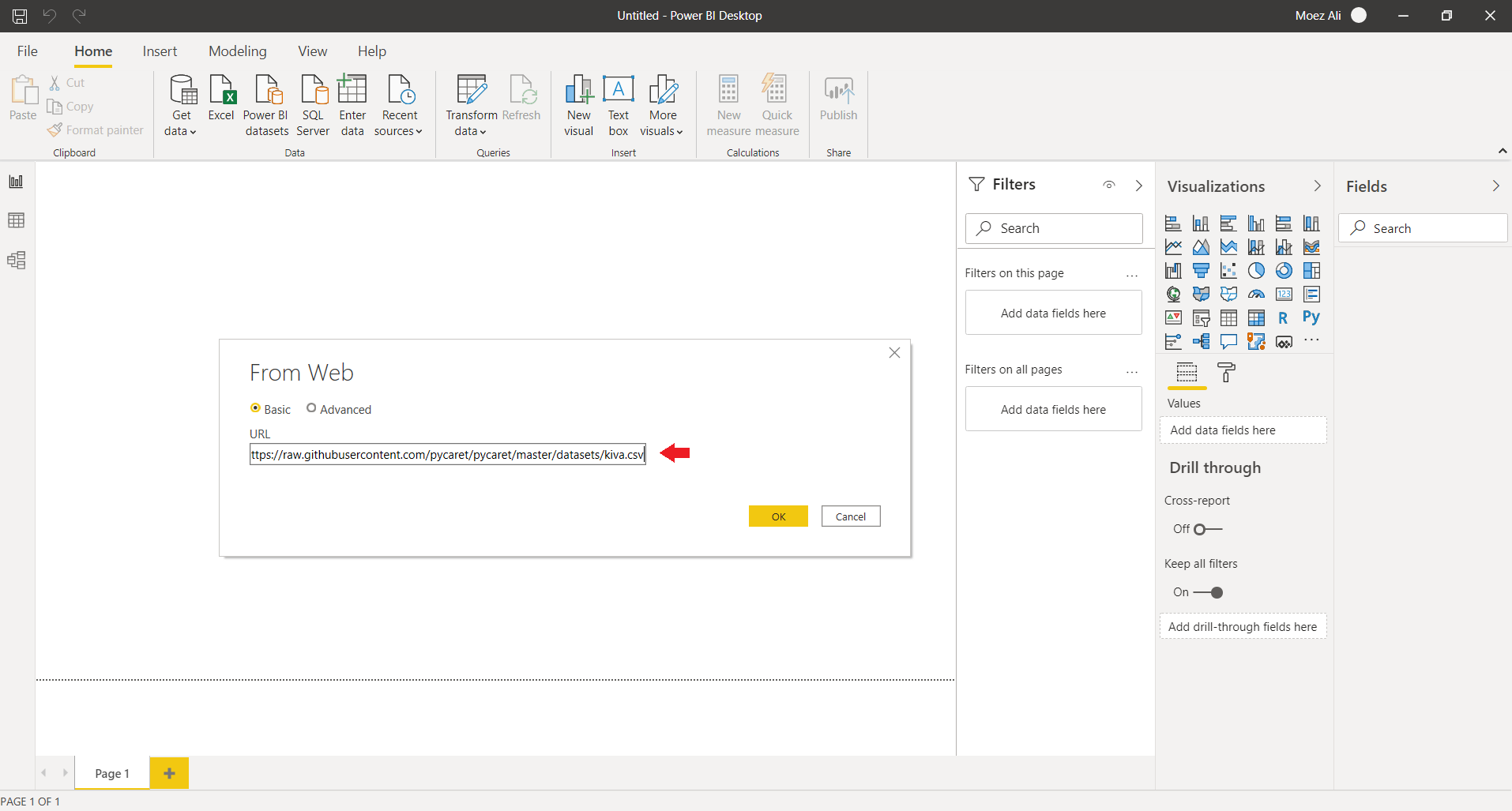
Link to csv file:
https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/kiva.csv
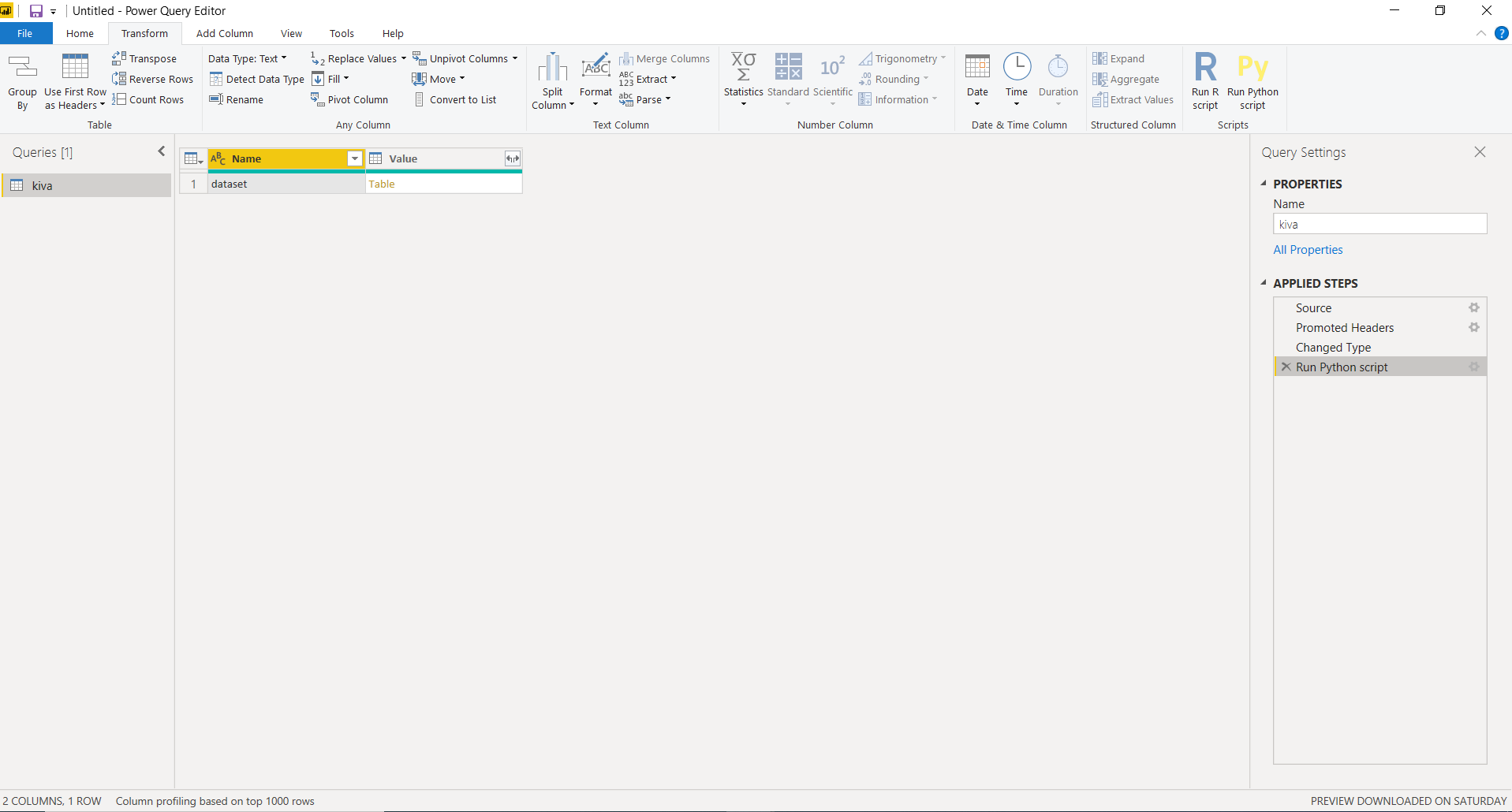
2. Model Training
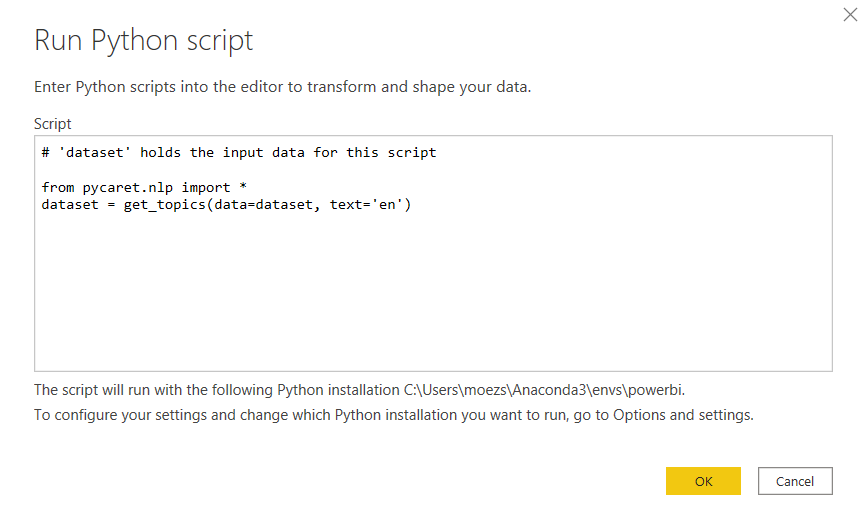
To train a topic model in Power BI we will have to execute a Python script in Power Query Editor (Power Query Editor → Transform → Run python script). Run the following code as a Python script:
from pycaret.nlp import *
dataset = get_topics(dataset, text='en')
There are 5 ready-to-use topic models available in PyCaret.


By default, PyCaret trains a Latent Dirichlet Allocation (LDA) model with 4 topics. Default values can be changed easily:
- To change the model type use the model parameter within get_topics().
- To change the number of topics, use the num_topics parameter.
See the example code for a Non-Negative Matrix Factorization model with 6 topics.
from pycaret.nlp import *
dataset = get_topics(dataset, text='en', model='nmf', num_topics=6)Output:


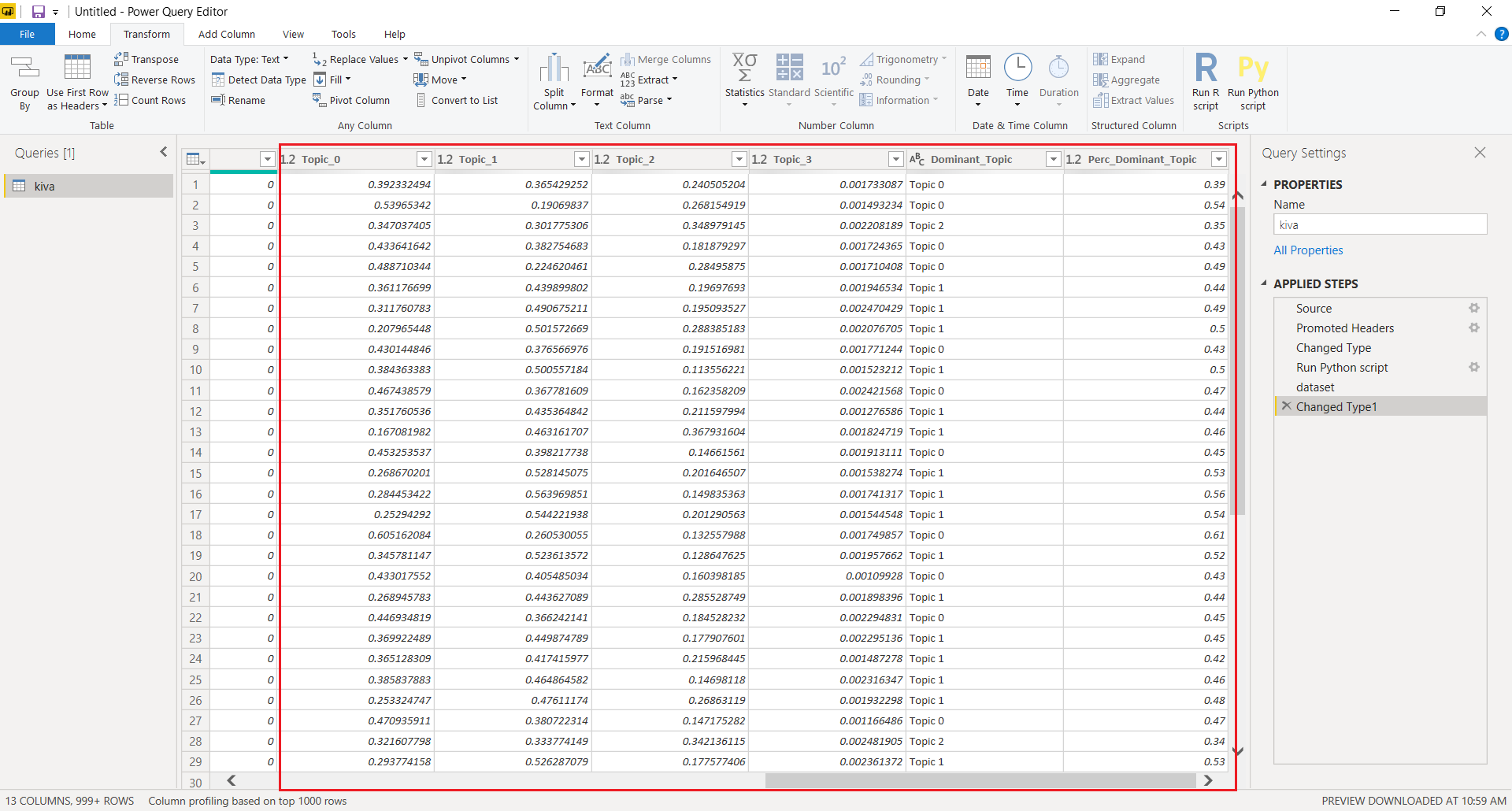
New columns containing topic weights are attached to the original dataset. Here’s how the final output looks like in Power BI once you apply the query.

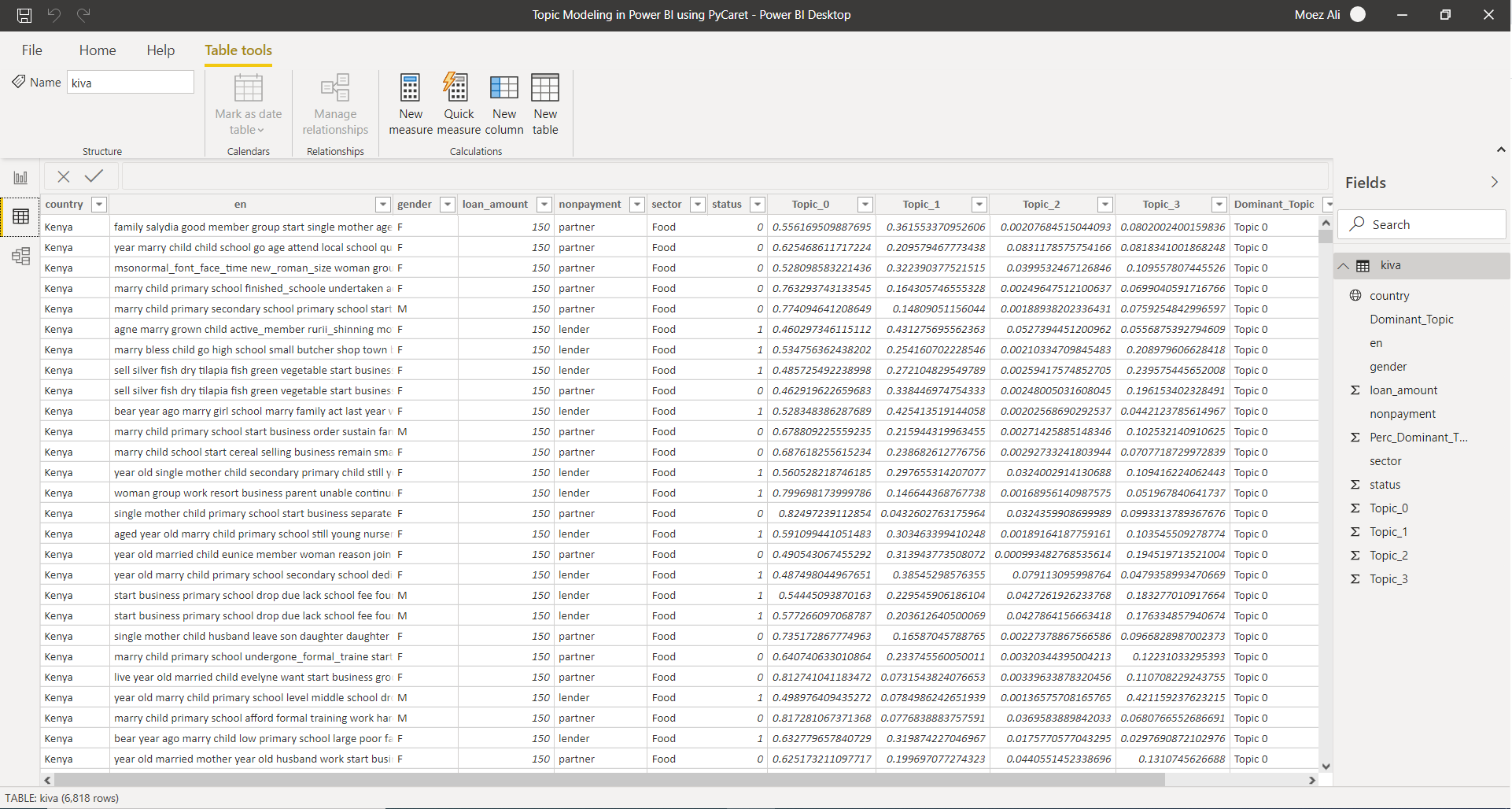
3. Dashboard
Once you have topic weights in Power BI, here’s an example of how you can visualize it in dashboard to generate insights:
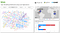
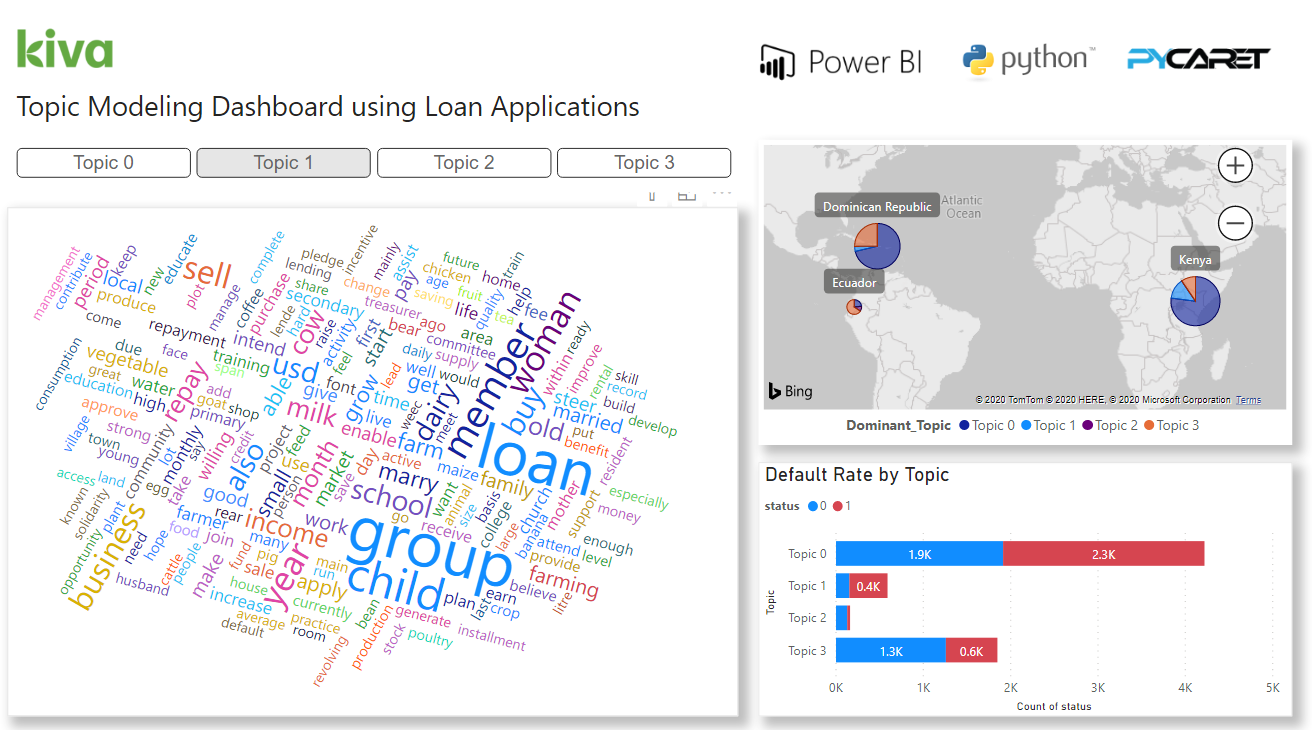

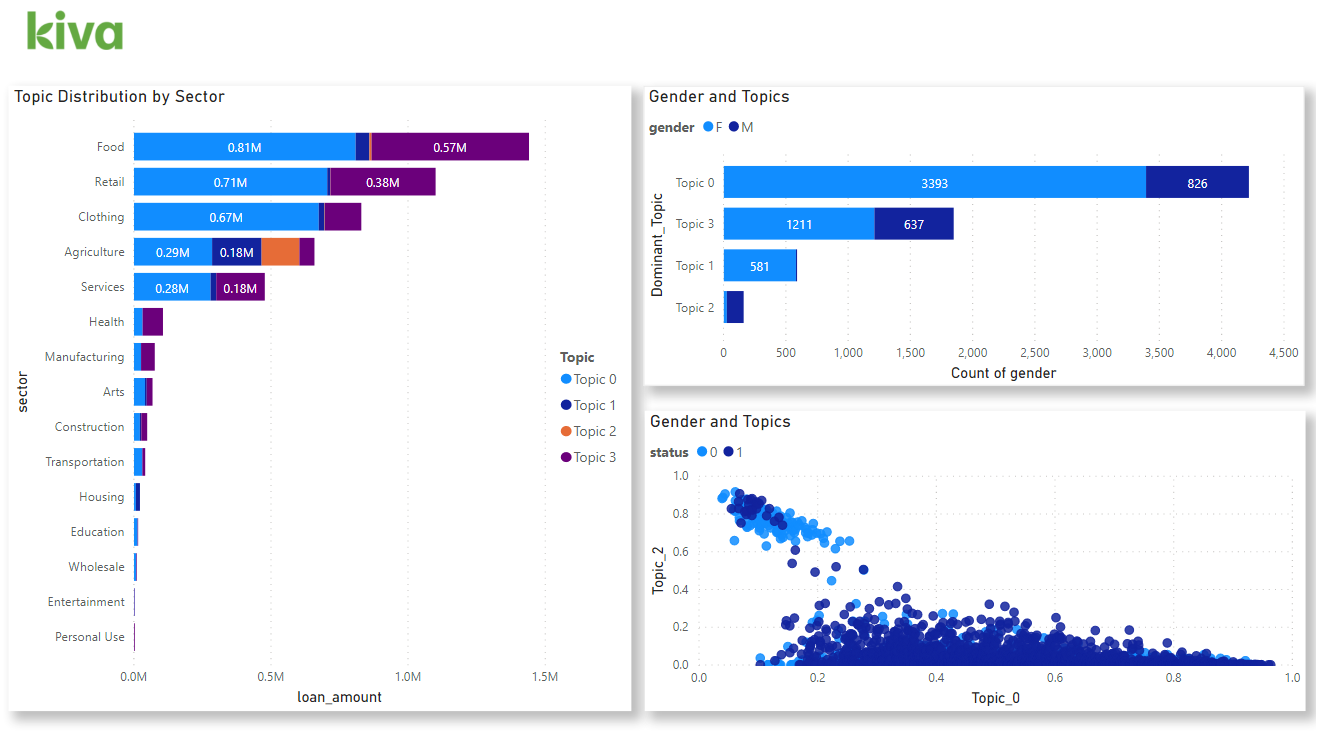
You can download the PBIX file and the data set from our GitHub.
If you would like to learn more about implementing Topic Modeling in Jupyter notebook using PyCaret, watch this 2 minute video tutorial:
If you are Interested in learning more about Topic Modeling, you can also checkout our NLP 101 Notebook Tutorial for beginners.
Follow our LinkedIn and subscribe to our Youtube channel to learn more about PyCaret.
Important Links
User Guide / Documentation
GitHub Repository
Install PyCaret
Notebook Tutorials
Contribute in PyCaret
Want to learn about a specific module?
As of the first release 1.0.0, PyCaret has the following modules available for use. Click on the links below to see the documentation and working examples in Python.
Classification
Regression
Clustering
Anomaly Detection
Natural Language Processing
Association Rule Mining
Also see:
PyCaret getting started tutorials in Notebook:
Clustering
Anomaly Detection
Natural Language Processing
Association Rule Mining
Regression
Classification
Would you like to contribute?
PyCaret is an open source project. Everybody is welcome to contribute. If you would like to contribute, please feel free to work on open issues. Pull requests are accepted with unit tests on dev-1.0.1 branch.
Please give us ⭐️ on our GitHub repo if you like PyCaret.
Medium : https://medium.com/@moez_62905/
LinkedIn : https://www.linkedin.com/in/profile-moez/
Twitter : https://twitter.com/moezpycaretorg1
Sign up for The Daily Pick
By Towards Data Science
Hands-on real-world examples, research, tutorials, and cutting-edge techniques delivered Monday to Thursday. Make learning your daily ritual. Take a look
A Medium publication sharing concepts, ideas, and codes.
Parameter and Model Uncertainty Quantification


In part 2 of this series, we are going to dive right into PyMC3 and learn how to apply it for uncertainty quantification (UQ) towards a non-linear model. For validation, we will also see how the Bayesian methods compare to the frequentist approach for parameter UQ. I’m going to assume you already optimized the parameters for your model. The model I will be using comes from part 1 of this series.
The libraries we will be using in this series are listed:
For those skipping to part 1 to here, or those that need a refresher from part 1, the nonlinear model is the solution to a first-order transient thermal response of a lumped-capacitance object (what a mouthful). …
Parameter and Model Uncertainty Quantification


Probabilistic programming languages such as Stan have provided scientists and engineers accessible means into the world of Bayesian statistics. As someone who is comfortable programming in Python, I have been trying to find the perfect Bayesian library that complements Python’s wonderful and succinct syntax.
One of the biggest challenges in learning new material and a new library is finding sufficient resources and examples. …
PYTHON FOR MACHINE LEARNING
Evaluating and Comparing Classifiers Performance


Machine Learning Classifiers
Machine learning classifiers are models used to predict the category of a data point when labeled data is available (i.e. supervised learning). Some of the most widely used algorithms are logistic regression, Naïve Bayes, stochastic gradient descent, k-nearest neighbors, decision trees, random forests and support vector machines.
Choosing the Right Estimator
Determining the right estimator for a given job represents one of the most critical and hardest part while solving machine learning problems. …
Say Goodbye to Spreadsheet Integration Headaches
DISCLAIMER: This post uses a product I made, API Spreadsheets, which I believe is truly the easiest way to do this. Feel free to check it out for yourself.

When you are working on a Data Science or Analytics project there are usually a ton of spreadsheets stored everywhere.
If you are like me, you probably do something like this:
- Download your Google Sheet as a spreadsheet
- Download your Dropbox spreadsheet
- Put them all in the same folder as your Desktop Files
- Use Pandas to read all the files
Which is an okay workflow. But then Steve in Marketing goes and changes some data in the Google Sheet. …
Techniques to handle larger-than-memory data.
Big data has been around since around 2005. Back then, if you wanted to manipulate big data, Hadoop was the hot new toy. Most likely, however, you would have to set up your own on-premise cluster and spend a few weeks or months configuring everything before being able to actually do something with the data.
Nowadays, things are different and as with everything that has do with technology, access to big data tools has been democratized.
Content from : https://towardsdatascience.com/topic-modeling-in-power-bi-using-pycaret-54422b4e36d6


0 Comments